<tr>
<td valign="top" class="class">
<a href="http://www.domain.com/url1" target="_new" rel="nofollow"><img style="border: 1px solid #000000;" name="name" id="id" src="http://domain.com/1.jpg" width="400" height="500" /></a>
</td>
<td valign="top" class="class">
<span class="title">title</span><br>
text<span class="new">text</span> <br>
<br>
<a href="http://www.domain.com/url2" class="class" title="title">title</a>, <a href="http://www.domain.com/url3" class="class" title="title">title</a> <br><br>
</td>

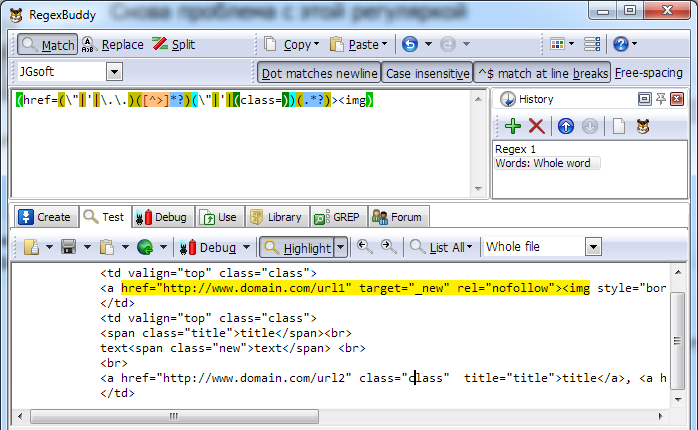

") Его исчезновение никак не отразилось на работоспособности регулярки...
Его исчезновение никак не отразилось на работоспособности регулярки...