XUC
второе пришествие
- Регистрация
- 3 Сен 2006
- Сообщения
- 868
- Реакции
- 570
- Автор темы
- #11
AMD рассказала о серверных ускорителях вычислений Instinct MI200 из нескольких кристаллов на CDNA 2
В рамках конференции Hot Chips 34 компания AMD поделилась деталями о серверных ускорителях вычислений серии Instinct MI200 на базе графических процессоров Aldebaran на архитектуре CDNA 2. Это первые графические решения AMD, в составе которых применяется компоновка из нескольких кристаллов (чиплетов), также известная как MCM-компоновка.
Источник изображений: AMD
- архитектура CDNA 2 с матричными ядрами второго поколения для ускорения вычислений FP64 и FP32. Они до четырёх раз увеличивают производительность операций FP64 по сравнению с предыдущим поколением серверных ускорителей AMD;
- передовая технология упаковки 2.5D Elevated Fanout Bridge (EFB), позволяющая до 1,8 раза увеличить количество ядер и до 2,7 раза повысить пропускную способность памяти по сравнению с предыдущим поколением серверных GPU AMD, а также обеспечить пиковую пропускную способности памяти в 3,2 Тбайт/c;
- третье поколение шины AMD Infinity Fabric; поддержка до 8 линий Infinity Fabric, которые обеспечивают связь между несколькими самими AMD Instinct MI200, а также процессорами AMD EPYC, в том числе третьего поколения, что обеспечивает системе унифицированную память CPU/GPU и повышает максимальную пропускную способность.

Для просмотра ссылки Войди или Зарегистрируйся
Блок-схема AMD Instinct MI200 GPU
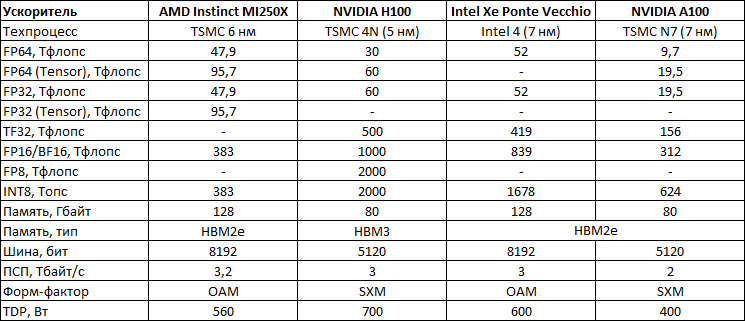
В составе графического процессора Aldebaran применяется скоростная шина xGMI. В составе каждого чиплета имеется движок VCN 2.6 и основной IO-контроллер, по четыре 1024-битных контроллера памяти HBM2e. На каждый чиплет также приходится по 8 Мбайт кеш-памяти L2, физически разделённой на 32 блока и по 64 Гбайт памяти HBM2e с пропускной способностью на уровне 1,6 Тбайт/с. Совокупный объём памяти HBM2e на GPU может достигать 128 Гбайт, а её пропускная способность составлять 3,2 Тбайт/с. Это на 1,2 Тбайт/с выше, чем у NVIDIA A100, оснащённой 80 Гбайт памяти HBM2e.Блок-схема AMD Instinct MI200 GPU
AMD Instinct MI200
Для просмотра ссылки Войди
AMD Aldebaran поддерживают 8 каналов Infinity Fabric. Один из них может использоваться для соединения CPU и GPU (по PCI Express). Оно рассчитано на согласованную передачу данных со скоростью 144 Гбайт/с. Показатель можно масштабировать до 500 Гбайт/с используя внешний канал Infinity Fabric с четырьмя подключёнными ускорителями AMD Instinct MI200 или с помощью PCIe 4.0 ESM AIC для пропускной способности на уровне 100 Гбайт/с.
Для просмотра ссылки Войди или Зарегистрируйся
Метрика производительности AMD Instinct MI200
AMD заявляет, что в зависимости от той или иной задачи Aldebaran может быть до трёх раз производительнее по сравнению с NVIDIA A100.Метрика производительности AMD Instinct MI200
Ускорители вычислений AMD Instinct MI200 на архитектуре CNDA 2 уже используются в составе суперкомпьютера Frontier эксафлопсного уровня, возглавляющего рейтинг самых производительных суперкомпьютеров мира TOP500. Он обеспечивает производительность на уровне 1,1 эксафлопс.
AMD также сообщила о планах по выпуску нового поколения ускорителей вычислений Instinct MI300. В них тоже будет использоваться чиплетная компоновка, но это уже будут APU — на одной подложке будут сочетаться кристаллы CPU и GPU. Для Instinct MI300 заявляется использование архитектур CDNA 3 GPU и Zen 4 и до 5 раз более высокая производительность в ИИ-задачах по сравнению с архитектурой CDNA 2.
Для просмотра ссылки Войди или Зарегистрируйся
Источник: Для просмотра ссылки Войди