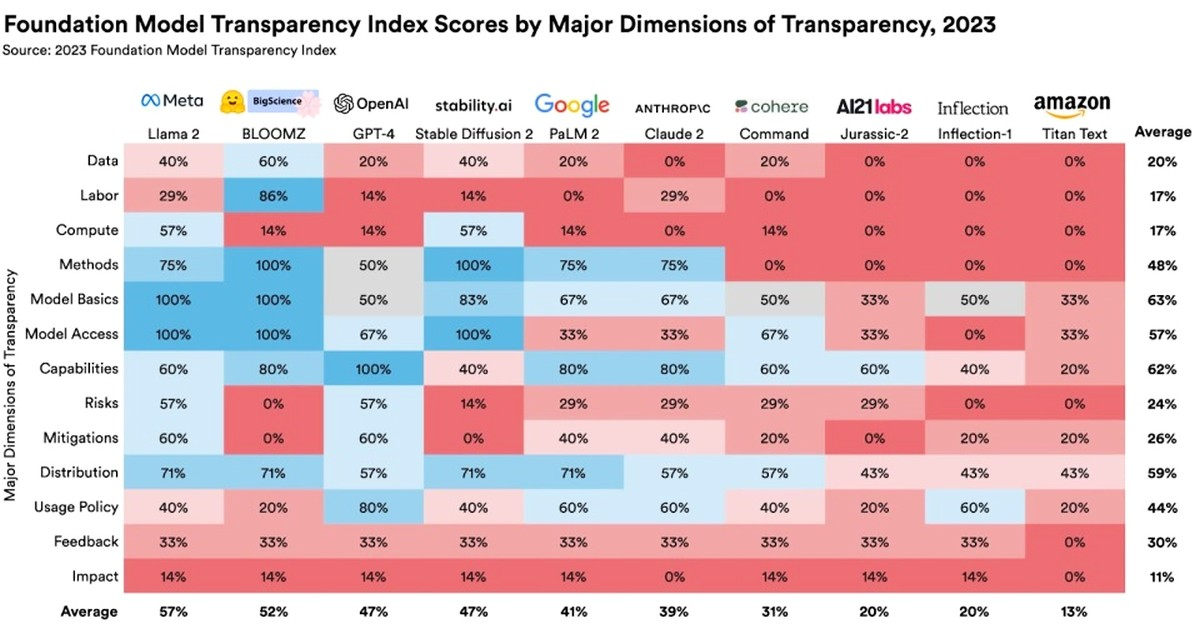
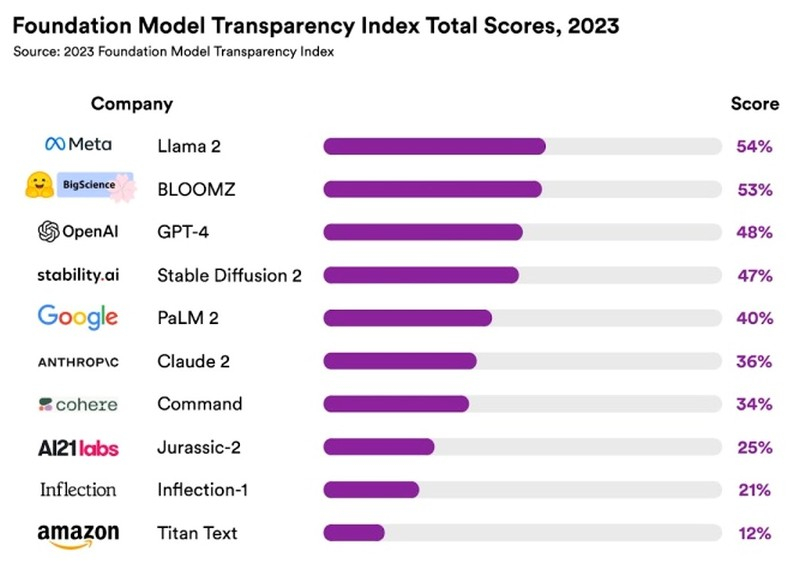
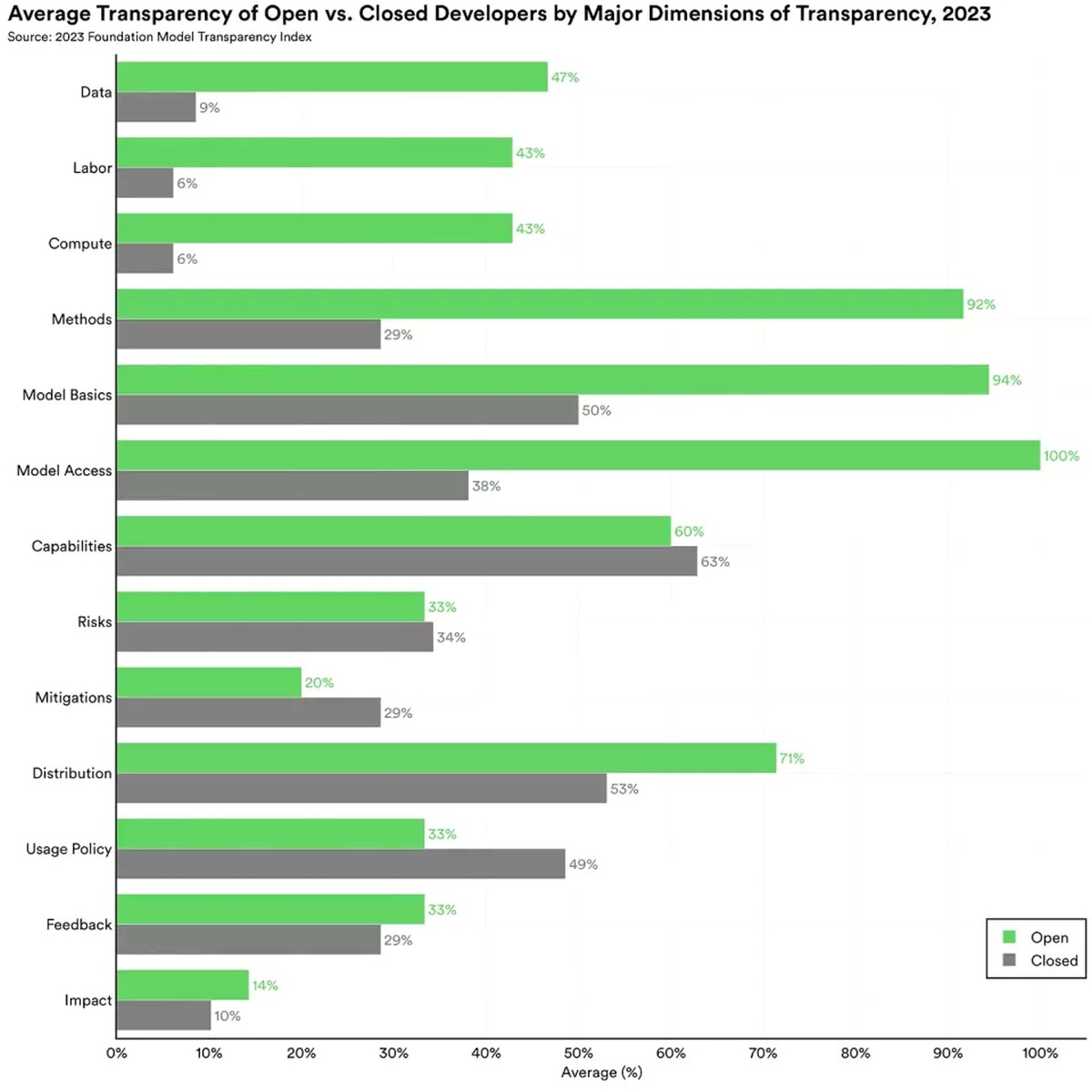
XUC
второе пришествие
- Регистрация
- 3 Сен 2006
- Сообщения
- 869
- Реакции
- 569
- Автор темы
- #31
Ampere и ещё около десяти разработчиков чипов создали ИИ-альянс AI Platform
Ряд разработчиков микрочипов объявили об объединении усилий в рамках организации AI Platform Alliance с целью ускорения внедрения передовых решений в области ИИ. Инициативу возглавляет Ampere Computing, развивающая экосистему серверных процессоров с архитектурой Arm.
В состав нового альянса вошли ещё около десяти компаний, большая часть из которых появилась относительно недавно: Cerebras Systems, Furiosa, Graphcore, Kalray, Kinara, Luminous, Neuchips, Rebellions и Sapeon. Ожидается, что в ближайшие месяцы список участников расширится.

Источник изображения: AI Platform Alliance
Цель проекта — сделать платформы ИИ более открытыми, эффективными и устойчивыми. Усилия будут сфокусированы прежде всего на разработке передовых аппаратных решений. В частности, речь идёт о специализированных ускорителях, которые позволят решать ИИ-задачи с более высоким быстродействием и при меньшем потреблении энергии по сравнению с GPU.
Ещё одной задачей группы станет оценка комплексных ИИ-платформ, основанных на совместных решениях участников альянса. Это могут быть, например, серверы, сочетающие процессоры Ampere с ускорителями машинного обучения, созданными другими членами AI Platform Alliance.
В долгосрочной перспективе планируется вывести на рынок более эффективные альтернативы современным вычислительным ИИ-системам, основанным на GPU. Предполагается, что это позволит удовлетворить растущий спрос на HPC-мощности для реализации ресурсоёмких проектов в ИИ-сфере.
Источник Для просмотра ссылки Войдиили Зарегистрируйся
Ряд разработчиков микрочипов объявили об объединении усилий в рамках организации AI Platform Alliance с целью ускорения внедрения передовых решений в области ИИ. Инициативу возглавляет Ampere Computing, развивающая экосистему серверных процессоров с архитектурой Arm.
В состав нового альянса вошли ещё около десяти компаний, большая часть из которых появилась относительно недавно: Cerebras Systems, Furiosa, Graphcore, Kalray, Kinara, Luminous, Neuchips, Rebellions и Sapeon. Ожидается, что в ближайшие месяцы список участников расширится.
Источник изображения: AI Platform Alliance
Цель проекта — сделать платформы ИИ более открытыми, эффективными и устойчивыми. Усилия будут сфокусированы прежде всего на разработке передовых аппаратных решений. В частности, речь идёт о специализированных ускорителях, которые позволят решать ИИ-задачи с более высоким быстродействием и при меньшем потреблении энергии по сравнению с GPU.
Ещё одной задачей группы станет оценка комплексных ИИ-платформ, основанных на совместных решениях участников альянса. Это могут быть, например, серверы, сочетающие процессоры Ampere с ускорителями машинного обучения, созданными другими членами AI Platform Alliance.
В долгосрочной перспективе планируется вывести на рынок более эффективные альтернативы современным вычислительным ИИ-системам, основанным на GPU. Предполагается, что это позволит удовлетворить растущий спрос на HPC-мощности для реализации ресурсоёмких проектов в ИИ-сфере.
Источник Для просмотра ссылки Войди